En algún momento, hace unos 3, 4 o 5 años (si lo pienso bien puedo empezar a encontrar situaciones y personas que actuaron de forma directa como disparadores) empecé a estudiar de qué manera adoptar todo eso que ofrecía el mundo DevOps con la fantasía de alcanzar cierto grado de automatización y magia que, en esa fantasía, viniera a resolver todos los problemas y vicios de la profesión. Claramente, estaba equivocado (por decir lo mínimo).
Luego de darme la cabeza contra la pared en más de una oportunidad la opción lógica fue intentar la deconstrucción de esas ideas.
Tras mucha lectura y charlas encontré material y planteos que me permitieron tener una comprensión, me gustaría creer, mejor acabada. (Sin dudas encontré mucha claridad y profundidad en el libro “Practice of Cloud System Administration, The: DevOps and SRE Practices for Web Services, Volume 2” de Thomas A. Limoncelli, Strata R. Chalup y Christina J. Hogan)
También investigué un poco sobre modelos de maduración. Otra vez, muchísimos puntos de vista, escalas, conceptos, etc. Opté por tomar lo que me pareció una escala más simple y que me permite cuantificar mi propia situación y el progreso fácilmente.
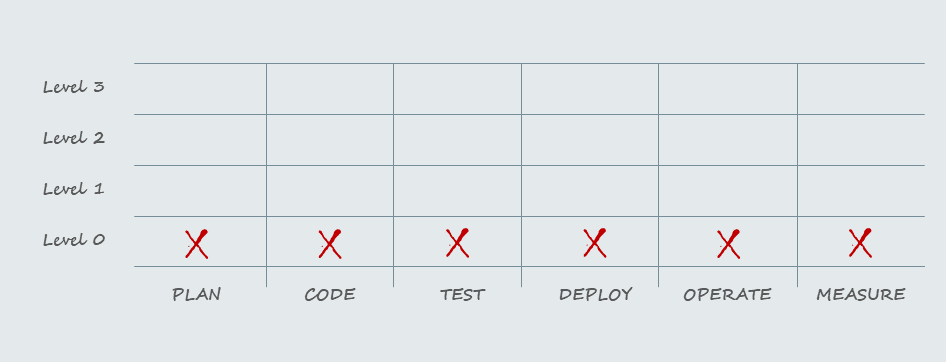
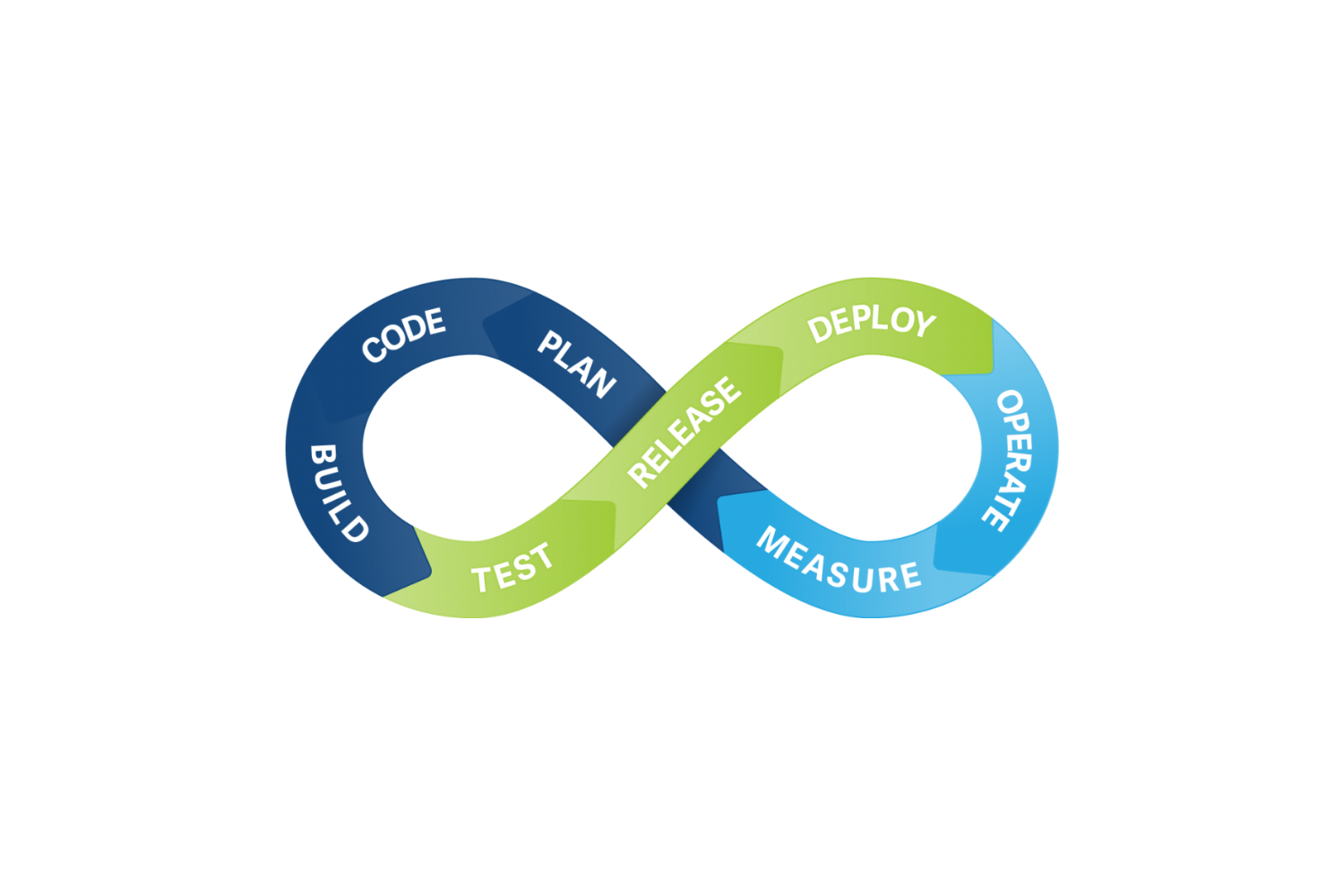
Me concentré en seis etapas del desarrollo.

Posiblemente, a medida que logre madurar las etapas, Build y Release puedan ser etapas individuales.
Y luego consideré 4 niveles de maduración o estados para cada etapa.
- Nivel 0: no existe automatización de ningún tipo. Todos los procesos de desarrollo son manuales. Los deploys son manuales. La reversión de los deploys, cuando es posible, también es manual.
- Nivel 1: automatización incipiente. Los deploys siguen siendo manuales, pero con procedimientos estandarizados. La reversión (rollback) sigue siendo manual. La recuperación de desastres es manual también y es un proceso complejo y lento. La auto-reparación (self-healing) es imposible porque la infraestructura se maneja manualmente.
- Nivel 2: la construcción y testeo del código es automático. Los deploys se automatizan. La infraestructura aún no está automatizada. Se pueden hacer reversiones deployando versiones previas. Recuperación de desastres de forma manual y lenta ya que la infraestructura se reconstruye, también, manualmente. Sin auto-reparación.
- Nivel 3: automatización completa de la infraestructura, compilación y el deploy. Tests para validar consistencia. Reversión sencilla de forma automática. Recuperación de desastres posible gracias a nuevos deploys de código e infraestructura. La auto-recuperación se hace posible.
Mi intención, tomándome algunas licencias, es aplicar alguna escala para tener un indicador de dónde me encontraba/encuentro hoy y cómo puedo hacer para mejorar mis procesos.

En algún momento partí entonces desde ahí. Cabe aclarar que no se debe confundir prácticas individuales con trabajo en empresas o agencias, en donde las dimensiones de los equipo y proyectos pueden o no tener relación.
El objetivo se convirtió entonces en automatizar los procesos de mi flujo de trabajo para reducir riesgos. Apunto a que cada cambio en las metodologías y herramientas sirvan para dar un paso seguro hacia adelante.
Uno de esos pasos en los que trabajé primero fue en los deploys, en el proceso y momento específico de la bajada de código a producción (teniendo presente la imagen anterior, claro). Si bien el objetivo último debería ser que los deploys sean realmente continuos y ceremonia-free. Concuerdo con la idea que plantea que los deployments tiene que ser lo más cercano posible a un no-evento.
Intentaré entonces documentar el recorrido y los problemas (y errores) con los que tuve y tengo que lidiar partiendo con el siguiente como mi punto de partida.