Con mi instancia de Jenkins ya instalada, lo siguiente fue agregar algunos plugins para acompañarme en lo que sería mi primer proyecto junto a la herramienta.
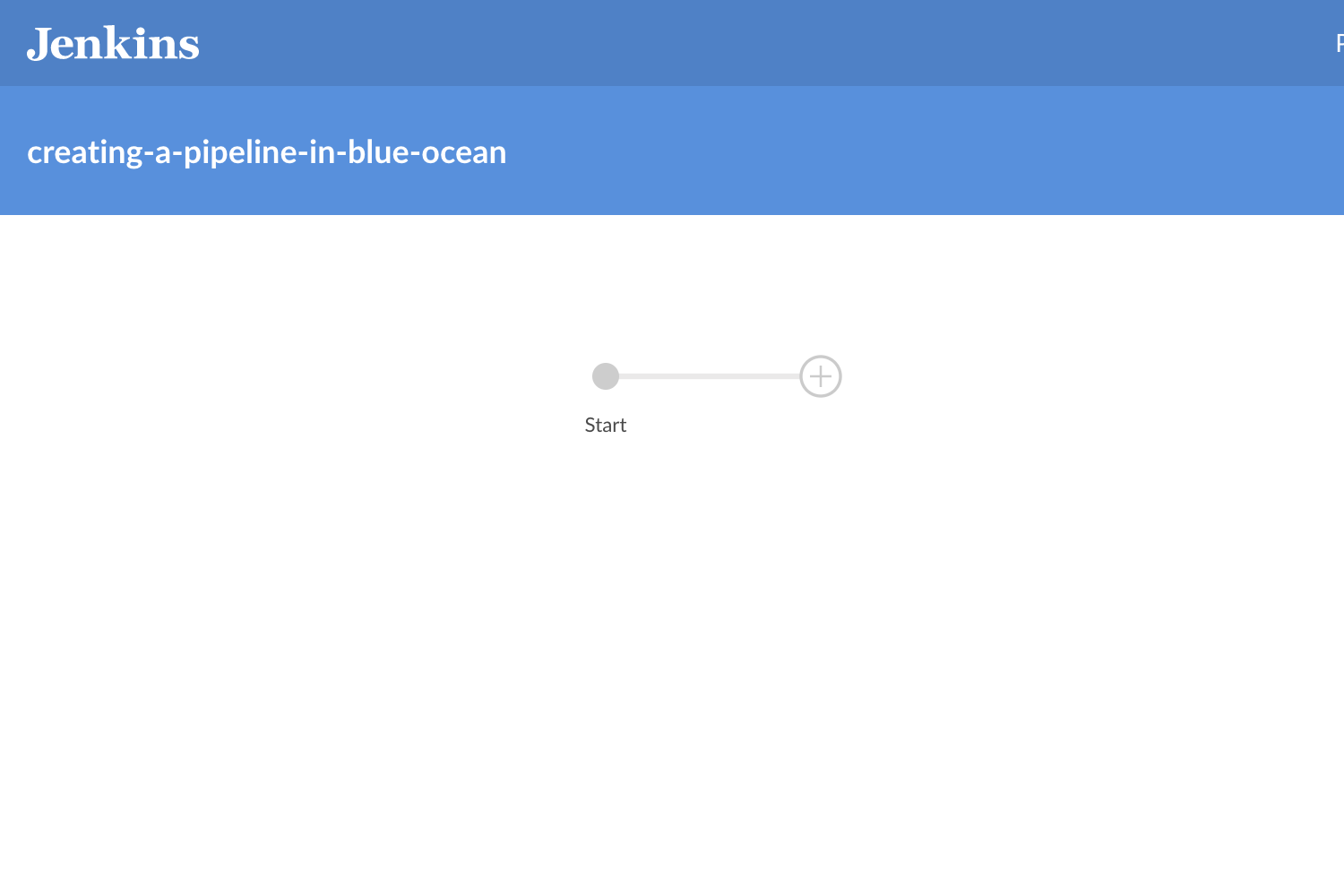
Lo último que habíamos visto era que teníamos nuestro dashboard más cercano a vacío que reluciente.
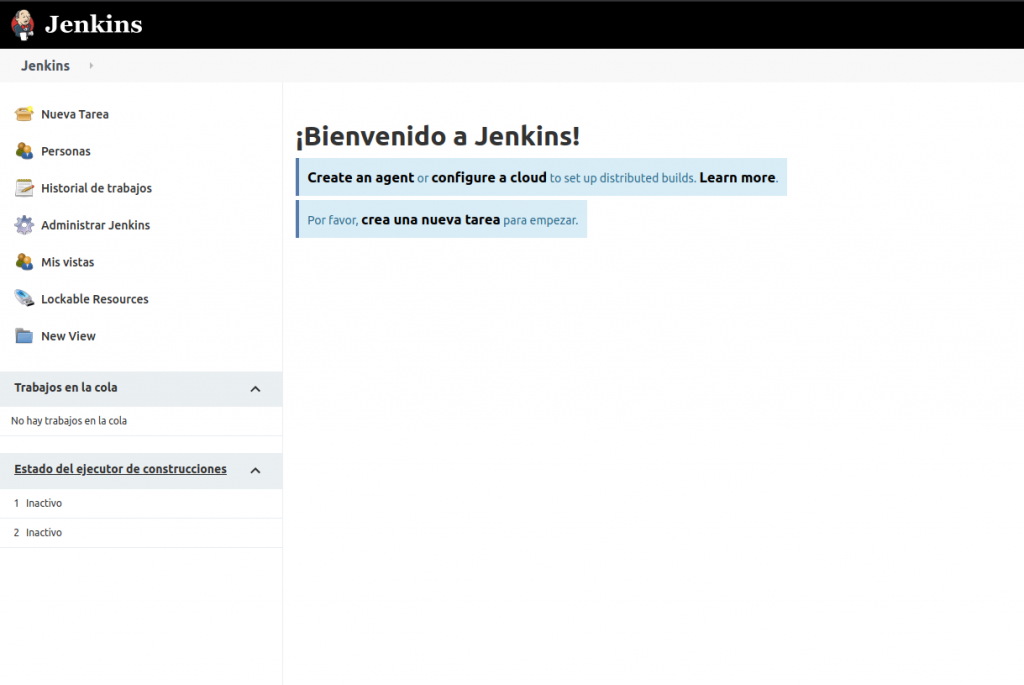
Como dije, voy a instalar algunos plugins que considero vitales para dar el siguiente paso en cuanto a las automatizaciones que estoy/estuve/estaré recorriendo.
Vamos entonces a «Administrar Jenkins».
Y luego a:
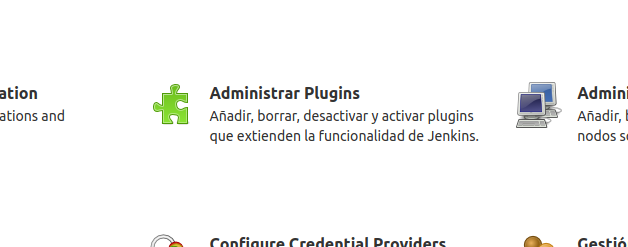
Vamos a buscar en la solapa de Disponibles. El primer plugin de hoy será Blue Ocean. Aquí las instrucciones oficiales.
Una vez que haya terminado de instalar, en nuestro menú tendremos una nueva opción.

Y si hacemos click, veremos la interfaz gráfica de Blue Ocean.
Aquí voy a abrir un primer paréntesis (uno de tantos que habrán). Siguiendo con el plan de automatizar y mejorar procesos, el objetivo inicial del uso de Jenkins lo concentraré en una acción muy específica: deploys.
Voy a crear entonces el primer pipeline para un repositorio que no estuvo nunca integrado con Jenkins. Por suerte la documentación es bastante amigable.
Primero tenemos que elegir en qué servicio o host tenemos el repositorio.
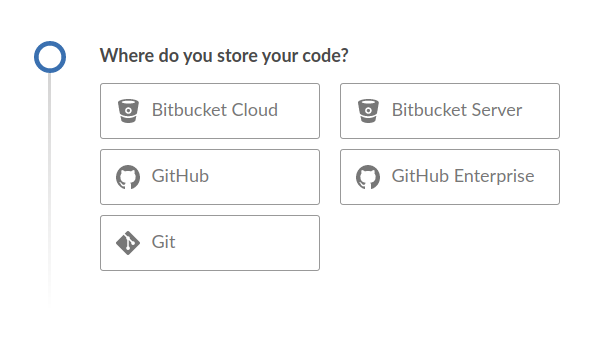
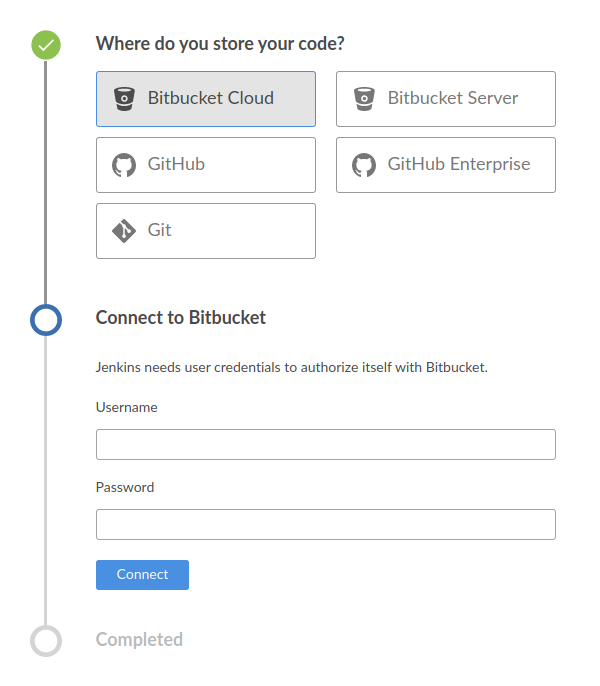
Una vez elegido, las credenciales. Yo usaré Bitbucket en este ejemplo.
Nos muestra ahora los teams u organizaciones disponibles.
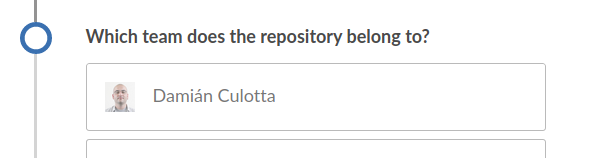
Elegimos el correcto y luego buscamos el repositorio.
Seleccionamos y vamos a crear el primer proyecto.
Como este repositorio no tiene un Jenkinsfile con el pipeline creado, me ofrece la posibilidad de definir uno.
Voy a volver al dashboard sin hacer nada aquí.
Hasta aquí sólo logré conectar mi repositorio, pero nada va a suceder.
Momento de retomar la línea argumental inicial del post. Vamos a instalar dos plugins adicionales que voy a necesitar antes de avanzar con mi pipeline.
Primero iré con Global Slack Notifier que como se puede deducir, es para notificar vía Slack si comenzó la ejecución de un pipeline y su resultado final.
El segundo plugin es Ansible . Esa es la herramienta con la cual voy a ejecutar las operaciones de despliegue/bajada del código (más adelante volveré sobre esto para ampliar dos detalles pero aquí pueden leer si no están familiarizados con la herramienta).
Si miramos lo hecho, instalé 3 plugins y pude asociar un repositorio sin pipeline aún (concepto con el cual podríamos no estar del todo familiarizados, pero que podemos reforzar aquí).
Vamos a concentrarnos ahora en el deploy más sencillo. Imaginemos que tenemos un sitio de una página, en html estático. Es más, se trata de un sitio que se desplegaba a su entorno por FTP/SFTP e incluso no estaba versionado.
Quizás pueda sonar exagerado para algunos hablar de sitios en esas condiciones. Lamento decepcionar diciendo que sólo en los últimos dos meses encontré animalitos de esas razas vivitos y coleando (ya habrán posts sobre experiencias de auditorías y otros elementos arqueológicos).
Retomo. Sitio html estático, que no estaba versionado y que se deployaba a mano por FTP. Tengo Blue Ocean listo y tengo el repositorio ya conectado a Jenkins.
Voy a ir con la parte más sencilla, configurar el plugin de Slack para que me notifique cuando se dispare un pipeline.
Vamos entonces a nuestro Slack y vamos a la gestión de aplicación. Allí agregaremos Jenkins y crearemos la integración.
Vamos a configuración (yo ya tenía creada la integración).
Si la editamos (o cuando la creamos) tenemos acceso a dos parámetros que son los que nos interesan.
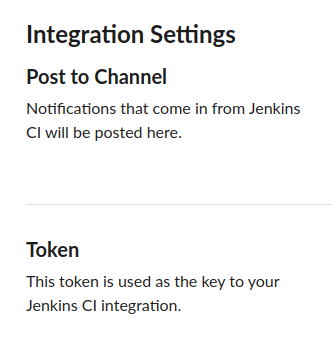
El token es lo que vamos a necesitar del lado de Jenkins. Volvamos para allá entonces. Vamos a la configuración general y hacemos scroll hasta el final. Allí tendremos:
Ahora vamos a agregar credenciales.
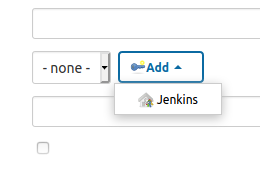
Y nos aparecerá este formulario.
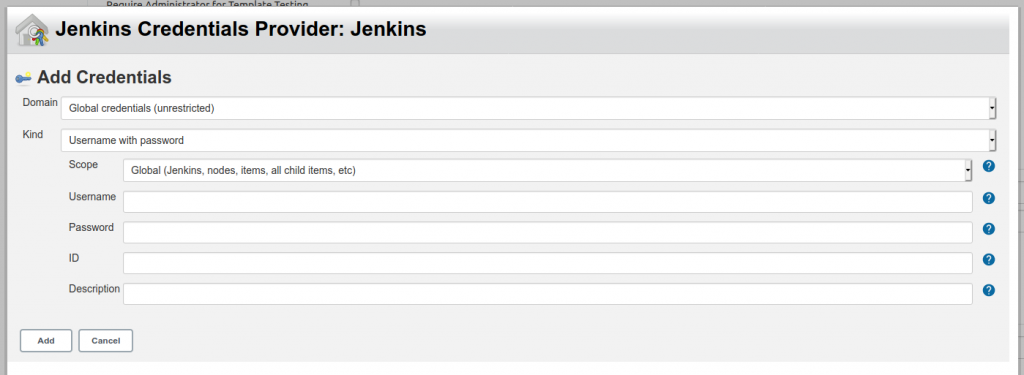
Debemos cambiar el valor de Kind a “Secret text”. En Secret ingresamos el token que copiamos en Slack. ID puede quedar vacío. La descripción nos sirve para identificar el token.
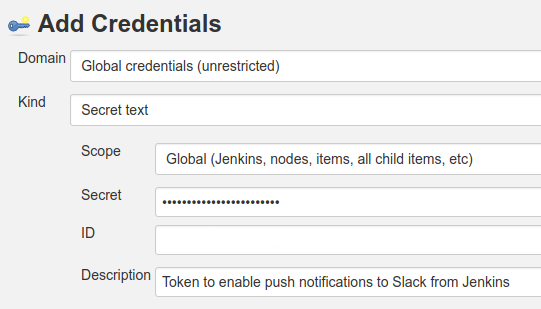
Grabamos y volvemos al formulario anterior, en donde seleccionaremos nuestra credencial del dropdown. Deben ingresar el nombre del Workspace que estén usando y el canal en el que se publicará (aunque debería salir de la integración, pero no lo probé).
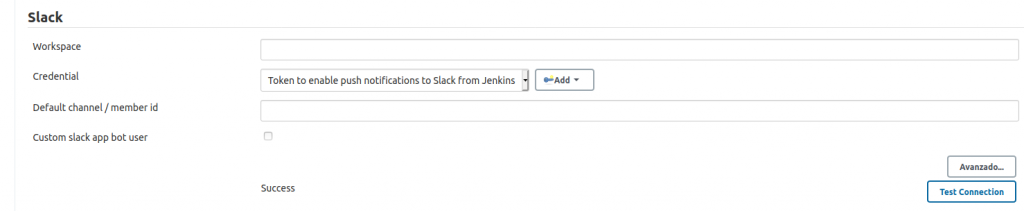
Si hacen click en Test Connection, deberían ver el Success aquí.
Y si van a Slack, al canal asignado, un mensaje parecido a este.

Segundo plugin listo.
Ahora vamos por el último protagonista de este post: Ansible.
Se juntarán ahora todos los aspectos anteriores. Vamos a crear nuestro primer pipeline (que es tan básico que posiblemente el nombre le quede grande). Este Pipeline lo que hará será revisar el repositorio por cambios, cada cierto tiempo, y cuando detecte alguno, va a ejecutar un playbook de Ansible. En ese Playbook voy a definir los comandos necesarios para que se disparen las acciones de acceso al servidor remoto y se haga, en este caso, una actualización del código desde el repositorio en cuestión.
Este párrafo permite abrir una cantidad importante de temas, pero vamos a hacerle caso a Jack y vamos a ir por partes.
Para que Jenkins preste atención al repositorio, necesitamos crear el pipeline desde el propio Jenkins o debemos crear el archivo Jenkinsfile en la raíz de nuestro repositorio.
Siguiendo con el ejemplo que mencioné más arriba, voy a crear el archivo con este contenido:
pipeline {
agent any
triggers {
pollSCM('*/15 * * * *')
}
stages {
stage('Deploy') {
when {
branch 'master'
}
steps {
slackSend(color: 'good', message: "${env.JOB_NAME} - ${env.BUILD_DISPLAY_NAME} - Iniciando deploy")
ansiblePlaybook(playbook: '/path/a/mis/playbooks/proyecto/produccion.yml', colorized: true, inventory: '/path/a/mis/playbooks/hosts')
}
}
}
post {
success {
slackSend(color: 'good', message: "${env.JOB_NAME} - ${env.BUILD_DISPLAY_NAME} - Funcionó correctamente")
}
failure {
slackSend(color: 'danger', message: "${env.JOB_NAME} - ${env.BUILD_DISPLAY_NAME} - Hubo un problema con el deploy")
}
}
}Si viéramos esto en Jenkins, sería algo así:
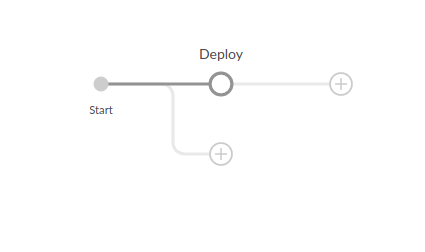
Y el paso específico del deploy.
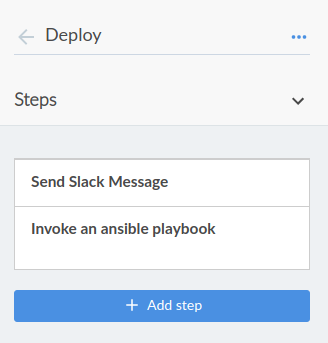
Como dije antes, Jenkins buscará cambios en el repositorio cada 15 minutos, si los detecta, cuando sean del branch Master, me notificará que comenzará un deploy (despliegue) y lo hará invocando un playbook de Ansible que yo tengo en en el path que allí especifico.
Si todo sale bien, me avisará por Slack del éxito. Si hay un error, me lo notificará también.
Veamos ahora un primer ejemplo de deploy usando Ansible y git.
---
- name: Deploy del branch Master a Producción
hosts: www.misitio.com.ar
vars:
directory: /var/www/html
tasks:
- name: Git pull
git:
repo: 'git@bitbucket.org:barbanet/misitio.git'
dest: '{{directory}}'
update: yes
version: master
- name: Garantizo permisos de todo el directorio
file:
dest: '{{directory}}'
state: directory
owner: miusuario
group: www-data
recurse: yes
- name: Ejecutamos el garbage collector de Git
command: git gc
args:
chdir: '{{directory}}'
¿Y cómo sabe Ansible a dónde y cómo debía conectarse? Para eso está el archivo de inventario especificado también en el Jenkinsfile.
En ese archivo encontramos la definición de todos nuestros hosts. Por ejemplo, para www.misitio.com.ar tendría este línea:
www.misitio.com.ar ansible_ssh_host=256.256.256.256 ansible_ssh_port=22 ansible_ssh_user=miusuarioLe decimos que para ese nombre de host, la IP es 256.256.256, que se conectará en el puerto 22 y lo hará con el usuario miusuario.
No hay password porque el usuario tiene ya definido lo que corresponde a nivel de sistema operativo, pero si lo hacen por Ansible, lean sobre cómo manejar correctamente información sensible.
Ahora nos resta mergear o pushear (si no tienen políticas sobre los branches) un cambio al branch master.
Si todo salió bien después del deploy, en Slack tendremos los mensajes pertinentes y si miramos en Jenkins, deberíamos tener algo así.
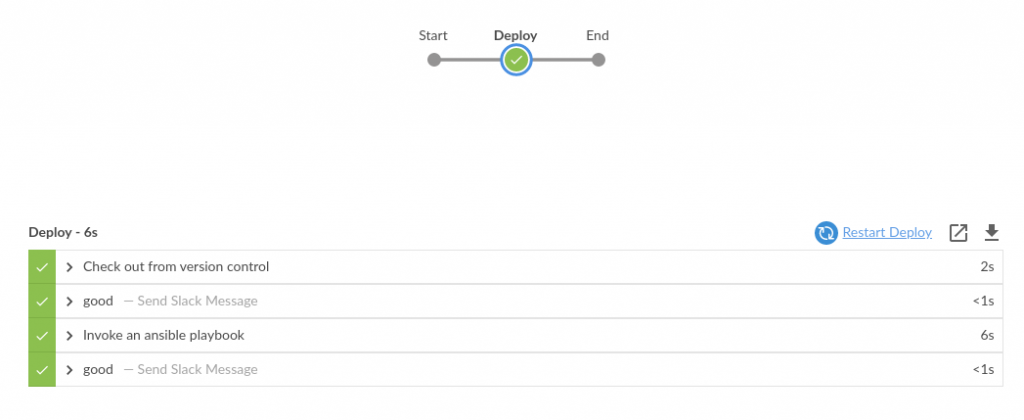
¿Qué hemos logrado entonces hasta aquí?
Pasamos de un deploy manual a uno automático, que luego de cumplir una regla (el código es mergeado al branch master) se despliega automáticamente (o se cancela ante falla) y me notifica de en ambos casos.
He seguido la idea de adoptar nuevas herramientas eligiendo una que se integre sin problemas a lo ya existente y que requiera la menor cantidad de cambios en lo que ya está funcionando. Claramente, hubo un cambio grande al instalar Jenkins y configurarlo, pero es algo de una sola vez. De aquí en más, cada deploy se seguirá haciendo como antes, pero con menos participación humana, por lo que se reduce la posibilidad de error y se gana tiempo.
No hace falta aclarar que esto es apenas la punta de la punta del iceberg de lo que podemos hacer con Jenkins. La intención es ir dándole mayor protagonismo en otras tareas. Lo mismo sucede con Ansible. Ambas son herramientas muy potentes (en mi caso soy un usuario básico que aprende un poco cuando necesita hacer algo nuevo o muy específico).
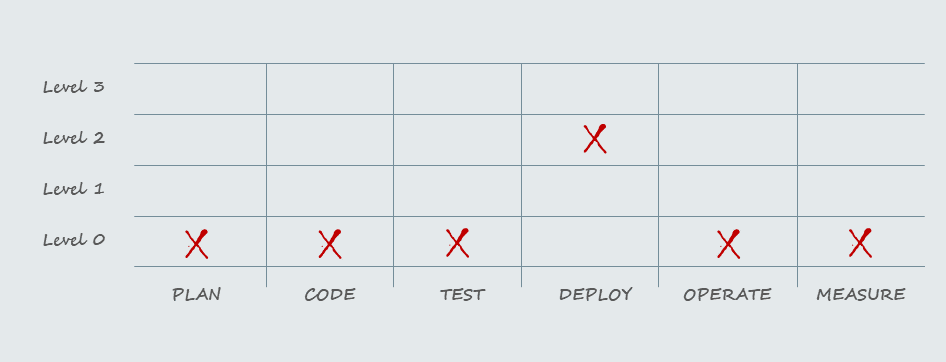
Si retomamos el cuadro en donde había separado en 6 etapas y 4 niveles de maduración del proceso DevOps, con esto podríamos hacer una corrección.
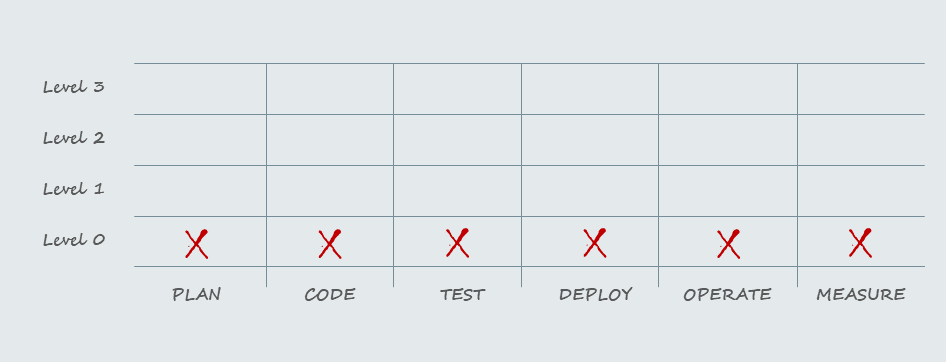
Desde ahora, nivel 0 para los deploys ya no aplica.
En el nivel 1 el deploy sigue siendo manual con proceso estandarizado pero el rollback es manual. Tampoco aplicaría.
En el nivel 2 mencionaba que el deploy se automatiza. Pareciera que estoy cerca.
En nivel 3 la automatización llega hasta la infraestructura, cosa que no estoy haciendo en este ejemplo. Me pasé de largo.
Si pienso en el todo, debería ser nivel 1, pero los deploys alcanzan el segundo nivel ya que se automatizaron por completo. Voy a actualizar entonces el cuadro evolutivo.
Algunos comentarios finales
El ejemplo de arriba es básico en todos los aspectos y necesitarán trabajar y profundizar sobre varios asuntos, partiendo desde las herramientas mencionadas hasta seguridad. El objetivo primario del post es mostrar otra opción más para salir de los pasos manuales. Esta no es la única forma, ni la mejor, ni la más sofisticada, pero es un paso adelante.
¿Por qué es importante el paso adelante?. Porque entiendo que cuando hablo de automatización se trata principalmente de quitar riesgos y potenciales problemas a los flujos de trabajo que ya tengo. Es por eso que apunto (y adhiero) a que cada paso hacia adelante tiene que ser un paso adelante de forma segura. Agregar pasos que incorporan nuevos problemas no es el tipo de automatización al que aspiro.
Jenkins no es la única herramienta con la que pueden hacer este tipo de cosas, claramente. Incluso hay muchas soluciones SaaS que permiten hacerlo. No he probado tantas aún (ni por tanto tiempo) como para tener opiniones sólidas de otras alternativas.
Este tipo de herramientas y mejoras no son sólo para proyectos de X tamaño o presupuesto o equipos de tal o cual característica. Incluso si se trata de tu blog o sitio hecho de la forma más estática, implementar estas soluciones para simplificar y quitarle riesgo a tu operación (deployar código forma parte de la operación) debería estar (me gusta creer) en el mismo nivel de “tengo que usar control de versiones para mi código”.
Si no están seguros, además de leer y estudiar y preguntar (y participar en foros y demás lugares), traten de tener algún tipo de mentoría/persona de confianza para preguntarle. En mi caso, sobre Jenkins, siempre estaré agradecido con Gastón por mostrarme cómo instalar e integrarlo para validar código (y otras tantas lecciones), con Matías por ayudarme a comprender (y finalmente aceptar) cómo tener la herramienta en los flujos de trabajo con Magento, y por supuesto a Josevi que siempre me ayuda a poner a prueba estas cosas y a encontrar los puntos de mejora.